robots.txt是一份純文字檔案,用以告訴網路爬蟲程式,網站上的哪些特定頁面禁止爬取。
有些時候,網站主並不希望某些頁面被抓取,例如依不同條件排序的商品列表頁面、某些無意義的頁面,或是仍在測試階段的頁面等等,為避免搜尋引擎因為爬取這些頁面而耗費網站其他部分被抓取的時間,或是因爬取某些頁面而造成伺服器流量的負擔,便可以利用robots.txt文件來指示這些網路爬蟲(又稱作網路蜘蛛、爬蟲程式、網路機器人、檢索器)。
一、robots.txt如何運作
搜尋引擎的主要任務可以大概分成幾項:
- 爬取(檢索)網路上的各個網站並發現其中的網頁內容
- 將這些不同的網頁編成索引(將其收錄)
- 當使用者搜尋時,將索引中的網頁以適當的順序呈現
在開始爬取網站的內容前,搜尋引擎的網路爬蟲會先到網站根目錄下尋找這個robots.txt純文字檔,並根據其中所給予的指示,進行網站內容的爬取。
然而,robots.txt文件中的指示並不是強制的,Googlebot等較為正派的網路爬蟲會按照文件中的指示行動,但並不是所有網路爬蟲都會這麼做。並且應注意是否有某些指示不為特定搜爬程式採用。
當robots.txt文件不存在或是沒有內容時,都代表搜尋引擎可以抓取網站的所有內容。
搜尋引擎的檢索(crawling)跟索引(indexing)屬於不同的程序,如果希望網頁不被檢索,應使用robots.txt;若希望網頁不被索引,則應使用noindex meta 標籤或其他方式。
在robots.txt中禁止爬取某個網頁,對遵循指示的搜尋引擎來說,該頁就是沒有內容的,可能因此讓其排名下降或消失於搜尋結果,但並無法確保頁面不會出現在搜尋結果中,搜尋引擎仍有可能透過其他導入連結進入,使得頁面被索引。
User-agent: 爬蟲程式的名字
Disallow: 不應爬取的網頁網址
由於robots.txt的主要功用是告訴網路爬蟲哪些網頁「不能」爬取,所以如上面所寫的兩行指示所形成的規則就可以當作一個最簡單的robots.txt檔案了。
指定網路爬蟲後,針對目錄或檔案的指示,應分開寫成獨立的一行。而針對不同爬蟲程式的指示間,則用空行加以間隔,如下圖:
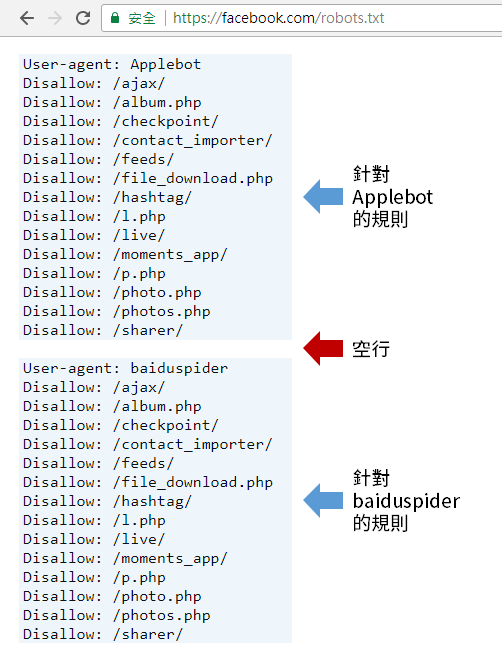
必要項目,你可以在每項規則中指定一或多個user-agent,從Robots Database與Google檢索器清單中可以找到大部分的user-agent名稱。此指令可以搭配 * 萬用字元使用,例如,User-agent: * 的範圍即包括了Adsbot以外的所有爬蟲程式。
註:Adsbot為Google用以評估到達網頁體驗的檢索程式,為避免影響廣告,系統會忽略全面排除的項目,所以若要防止Adsbot爬取網頁,需特別針對它撰寫規則
2. Disallow
每項規則至少要有一個Disallow或Allow的指令,Disallow用以表示禁止爬蟲程式的項目。若為網頁,應撰寫完整的相對路徑;若為目錄,則必須以/作為結尾。
3. Allow
每項規則至少要有一個Disallow或Allow的指令,Allow用以表示允許爬蟲程式的項目,可覆蓋以Disallow禁止的項目。若為網頁,應撰寫完整的相對路徑;若為目錄,則必須以/作為結尾。
4. Crawl-delay
非必要項目,用以告訴在開始抓取網頁前延遲多久,單位為毫秒。只是Googlebot會忽略這項規則,因為在Google Search Console中已經有關於限制檢索頻率的設定。
5. Sitemap
非必要,你可以透過這個指令指出XML網站地圖的位置,也可以同時提供多個網站地圖,分行列出即可,此項指令應使用絕對路徑。
在上面提到的Disallow與Allow指令中,可使用正規表達式裡面的 * 與 $ 字元,用途如下:
- * 可代表0或一個以上的任何有效字元。
- $ 代表網址結束。
四、常見的規則範例
下面以www.example.com為例,列出一些常見的規則,提供參考。
1. 禁止抓取整個網站
如下的規則會禁止所有爬蟲程式抓取整個網站(但不包括Google的Adsbot檢索器)。
Disallow: /
2. 允許抓取整個網站
如下的規則會允許所有爬蟲程式抓取整個網站的內容,沒有建立robots.txt檔案或是該檔案沒有內容也會有一樣的效果。
Disallow:
3. 允許單一爬蟲程式抓取整個網站
如下的規則會禁止baiduspider以外的爬蟲程式抓取整個網站的內容。
Allow: /
User-agent: *
Disallow: /
4. 禁止特定爬蟲程式抓取特定目錄
如下的規則會阻止Google的檢索程式(Googlebot)抓取以www.example.com/folder1/為開頭的所有網頁內容。
Disallow: /folder1/
5. 禁止特定爬蟲程式抓取特定頁面
如下的規則會阻止Bing的檢索程式(Bingbot)抓取www.example.com/folder1/page1.html此頁面的內容
Disallow: /folder1/page1.html
6. 指定特定字串結尾的網址
如下的規則可以封鎖任何以.gif為結尾的網址,亦可以應用在特定類型檔案的禁止。
Disallow: /*.gif$
五、如何建立robots.txt檔案
你可以使用幾乎所有的文字編輯器來建立robots.txt文件,或是利用robots.txt測試工具建立。但應避免使用文書編輯軟體,以免所儲存的格式或是不相容的字元引發內容剖析的問題。
此純文字檔的檔案名稱必須為robots.txt,檔名區分大小寫,且檔案只能有一個,必須放置於網站主機的根目錄下。
以https://www.example.com/ 為例,robots.txt的位置就必須為https://www.example.com/robots.txt。
子網域需各自建立其robots.txt檔案,如https://blog.example.com/ 應建立於https://blog.example.com/robots.txt
建立後的robots.txt檔案是公開的,任何人只要在根網域的後方輸入/robots.txt就可以看到網站禁止爬取的網頁是哪些,所以在建立檔案內的指令時要特別考慮這點。
六、robots.txt的SEO最佳做法
1. 確定你想要被檢索的頁面沒有透過robots.txt阻擋。
2. 透過robots.txt阻止檢索的網頁,當中的連結並不會被爬蟲經過,這代表,被連結的頁面如果沒有來自其他網頁的連結,該網頁不會被檢索,並且可能不會被收錄。
3. 如果想避免較敏感的資料出現在搜尋結果,不要使用robots.txt,應該使用其他方式如密碼保護或robots meta directives。
4. 搜尋引擎會快取robots.txt的內容,但通常會在一天內更新,如果你改變了該檔案的內容,並希望其盡快生效,你可以將其提交給Google。
5. 針對搜尋引擎爬蟲的指示好多!有robots.txt又有robots meta directives,兩者間的差別在於:robots.txt給予網路爬蟲關於搜爬網站目錄的指示;而robots meta directives則是針對個別頁面給予是否索引的指令。
发表评论
0 评论